使用重新搜索浏览器工具执行数据库搜索和分析
作者:阿吉特·辛格·雷纳
一个全功能的纯桌面GUI客户端,RedisInsight支持RediSearch。再研究是一个功能强大的Redis索引、查询和全文搜索引擎。它是最成熟、功能最丰富的Redis模块之一。通过RedisInsight,可以实现以下功能
- 多行用于构建查询
- 添加了在单行模式下使用“ctrl+enter”提交查询的功能
- 在索引选择器下拉菜单中更好地处理长索引名称
- 修复了查询字符串中带有空格的查询分页错误
- 支持聚合
- 支持模糊逻辑
- 简单和复杂条件
- 分类
- 标页码
- 计数
RedSearch允许您在数据集(散列)上快速创建索引,并使用增量索引方法快速创建和删除索引。通过索引,您可以以极快的速度查询数据,执行复杂的聚合,并按属性、数字范围和地理距离进行筛选。
步骤1。创建复述,数据库#
按照此链接使用Docker容器创建Redis数据库这与reresearchch模块的启用
步骤2:下载RedisInsight#
要在本地系统上安装RedisInsight,首先需要从Redis实验室网站下载软件。万博电竞客服
单击此链接访问允许您选择所选操作系统的窗体。

运行安装程序。web服务器启动后,打开http://YOUR_HOST_IP:8001,添加一个Redis数据库连接。
选择“连接到Redis数据库”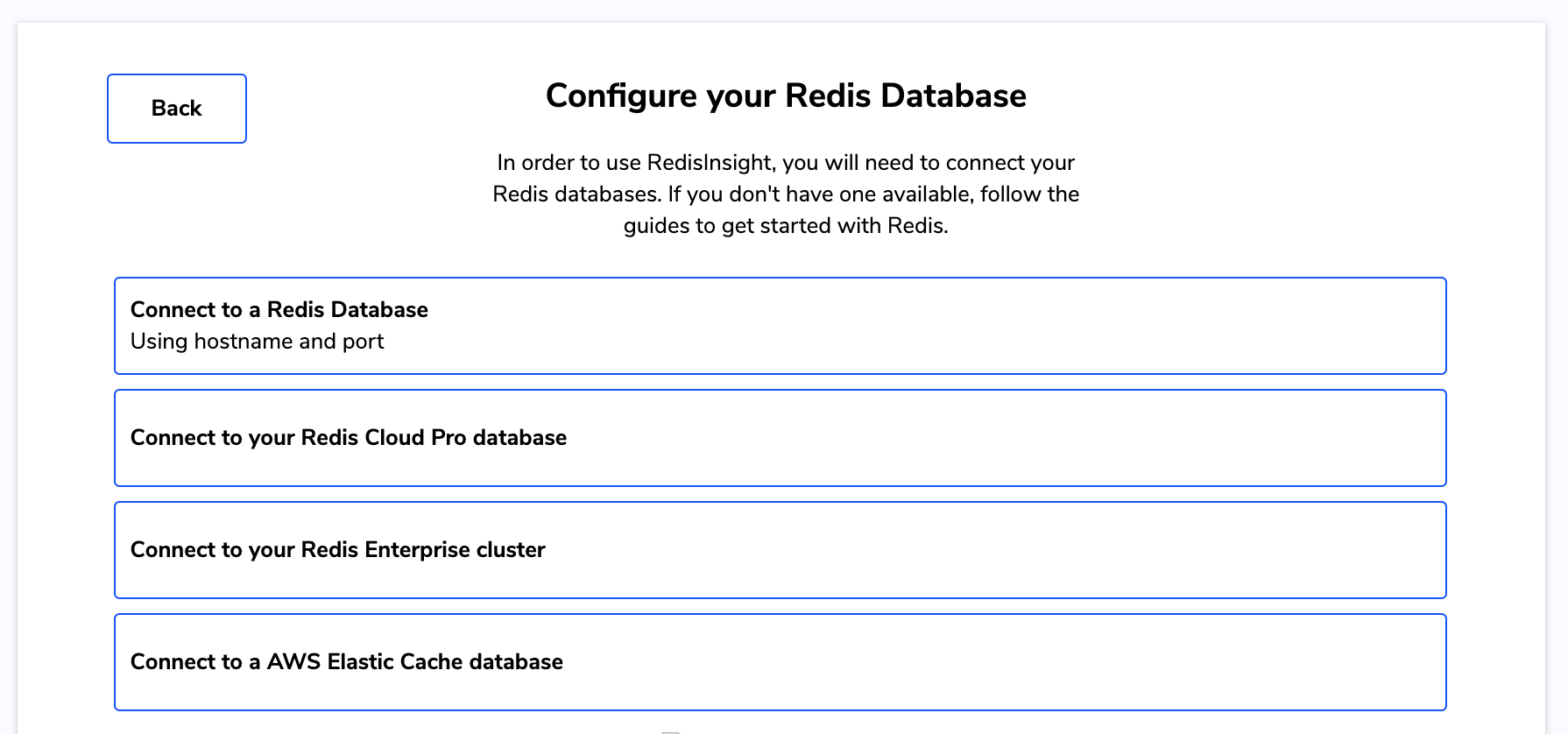
输入请求的详细信息,包括名称、主机(端点)、端口和密码。然后单击“添加REDIS数据库”。

我们将看两个数据集——一个是OpenBeerDB,另一个是电影数据集。
步骤3.OpenBeerDB示例数据集#
为了演示重新搜索,我们将使用OpenbeerDB数据集openbeerdb.com

让我们克隆存储库以访问数据集:
步骤4。安装先决条件包#
步骤5.导入数据#
步骤6:在RedisInsight浏览器工具下选择“RediSearch”#

运行以下查询:

您可以单击“{:}”以获得JSON视图,如下所示:


您可以下载CSV格式的数据。


查询:ABV高于5%但低于6%的所有啤酒#
啤酒被添加到按ABV加权的重新搜索索引中。因此,默认情况下,结果将按ABV从高到低排序。ABV和IBU都是可排序的,因此您可以在查询中使用sortby按这些字段中的任何一个排序结果

查询:ABV高于5%但低于6%的所有啤酒在规定限度内#

查询:找出ABV大于9%的爱尔兰麦芽啤酒和德国麦芽啤酒:#

步骤7.使用聚合#
聚合是一种处理搜索查询结果、对其进行分组、排序和转换并从中提取分析见解的方法。与其他数据库和搜索引擎中的聚合查询非常相似,它们可以用于创建分析报告,或执行facet search样式的查询。
例如,通过索引web服务器的日志,我们可以按小时、国家或任何其他细分为唯一用户创建报告;或者为错误、警告等创建不同的报告。
让我们运行聚合查询

让我们也看看Movie样本数据集。
步骤8。创建复述,数据库#
按照此链接使用Docker容器创建Redis数据库这与reresearchch模块的启用
第9步。安装RedisInsight#
点击这个链接在系统中本地设置RedisInsight
第十步。电影样本数据库#
在这个项目中,您将使用一个简单的数据集来描述电影,目前,所有的记录都是英语的。您将在另一个教程中学习更多关于其他语言的知识。
电影由以下属性表示:
电影id:此数据库内部的电影的唯一ID标题:电影的标题。情节:这部电影的摘要。体裁:电影的类型,目前一部电影只会有一个类型。发布年份:用数值表示电影上映的年份。评级:表示公众对这部电影的评价的数值。投票:票数。招贴画:链接到电影海报。imdb_id:中电影的idIMDB数据库
密钥和数据结构#
作为Redis开发人员,构建应用程序时首先要考虑的事情之一是定义键和数据的结构(数据设计/数据建模)。
在Redis中定义键的常见方法是使用特定的模式。例如,在这个应用程序中,数据库可能会处理各种业务对象:电影、演员、剧院、用户……我们可以使用以下模式:
业务对象:密钥
例如:
电影:001对于id为001的电影用户:001id为001的用户
对于电影信息,您应该使用Redis哈希.
Redis散列允许应用程序在单个字段中构造所有电影属性;此外,RedSearch将根据索引定义对字段进行索引。
步骤11.插入电影#
现在是向数据库中添加一些数据的时候了,让我们使用redis cli或复述,洞察力.
连接到Redis实例后,运行以下命令:

现在可以使用电影ID从散列中获取信息。例如,如果要获取标题,请执行以下命令:
你可以使用以下方法增加这部电影的评级:
但是,如何按发行年份、评级或片名获得电影或电影列表呢?
一种选择是读取所有电影,检查所有字段,然后只返回匹配的电影;不用说这是一个非常糟糕的主意。
然而,Redis开发人员经常在这里使用指向电影散列的集合/排序集合ag万博下载万博最新版本下载苹果结构创建自定义二级索引。这需要一些繁重的设计和实现。
这就是重新搜索模块可以提供帮助的地方,也是创建它的原因。
步骤12.重新搜索和索引#
RediSearch通过提供一种简单和自动的方式在Redis哈希上创建二级索引,极大地简化了这一点。(更多的数据结构最终会出现)
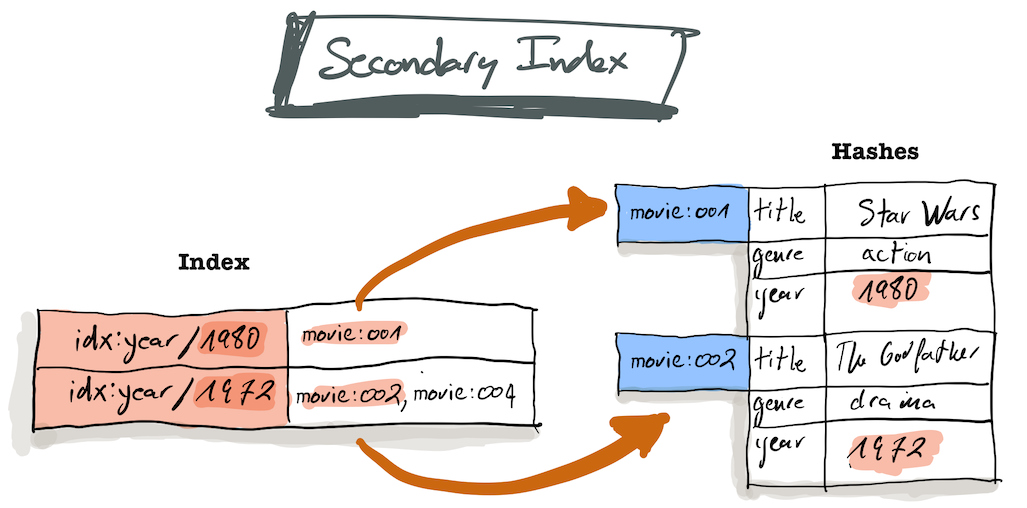
如果要查询某个字段,必须首先对该字段编制索引,然后使用“重新搜索”。让我们首先为电影的以下字段编制索引:
- 标题
- 发布年份
- 评级
- 体裁
创建您定义的索引时:
- 要索引的数据:全部散列用以开头的键
电影 - 要使用架构定义索引哈希中的哪些字段。
警告:不要为所有字段编制索引
索引占用内存空间,必须在主数据更新时更新。因此,请仔细创建索引,并使定义与您的需要保持最新。
步骤13。创建索引#

数据库包含一些电影和索引,现在可以执行一些查询。
查询:包含字符串的所有电影“战争"#

查询:使用RETURN参数限制查询返回的字段列表#
search命令返回以结果数量开始的结果列表,然后是元素列表(键和字段)。
正如你所看到的电影《星球大战5:帝国反击战》已找到,即使您仅使用“war”一词来匹配标题中的“Wars”。这是因为标题已作为文本索引,因此该字段为标记化的和是.
稍后在更详细地查看查询语法时,您将了解更多关于搜索功能的信息。
还可以使用返回参数,让我们运行相同的查询,并仅返回标题和发布年份:

查询:所有包含字符串“war but NOT the jedi”的电影#
添加字符串-绝地武士(minus)将要求查询引擎不要返回包含绝地武士.

步骤14:模糊搜索#
包含字符串"gdfather using fuzzy search"的所有电影

查询:所有的惊悚电影#

查询:所有惊悚片或动作片#

查询:所有在1970年到1980年间上映的电影(包括在内)#
FT.SEARCH语法有两种查询数字字段的方法:
使用过滤器参数
FILTER release_year 1970 1980返回2 title release_year

第15步。聚集#
查询:按年计算的电影数量#

查询:按年从最近到最老的电影数量#

附加链接#
- RediSearch项目
- RediSearch教程
- 电影数据库入门
- 使用RedisInsight的Slowlog配置
- 使用RedisInsight进行内存分析
- 使用RedisInsight浏览器工具可视化Redis数据库键
- 在RedisInsight中使用Redis Streams
